Next-Generation AI Infrastructure, Delivered as a Service.
From single GPU instances to enterprise clusters — NeoCloudz gives you the performance and control you need to build the future of AI.

Compute as a Service
Elastic Compute for AI and HPC Workloads
Run large-scale training, inference, and simulation workloads on demand.
NeoCloudz Compute as a Service gives you direct access to NVIDIA Blackwell infrastructure and H200 GPUs, backed by ultra-low-latency InfiniBand networking and NVMe storage.
- Bare-metal and virtualized GPU instances
- Auto-scaling and API-based provisioning
- Optimized for TensorFlow, PyTorch, JAX, and custom CUDA workloads
- Available in both shared and dedicated configurations

AI Cloud
Fully Managed AI Cloud for Generative and Predictive Models
Provision complete AI environments instantly — no manual setup, no infrastructure overhead. NeoCloudz AI Cloud combines compute, storage, and orchestration into one unified platform for training, inference, and continuous deployment.
- Generative AI (LLMs, diffusion models, multimodal architectures)
- Fine-tuning and experimentation
- MLOps pipelines and production inference
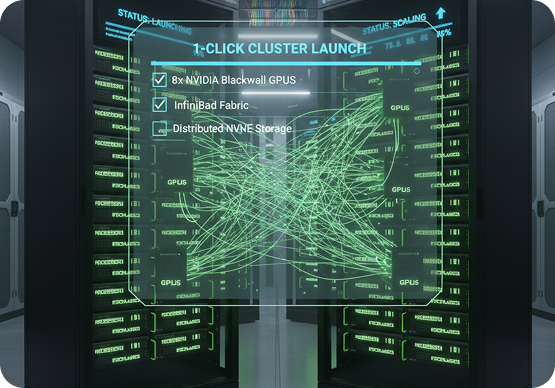
Self-Service AI Clusters
Instant Multi-Node Clusters — Built for Scale
Spin up clusters of NVIDIA Blackwell GPUs with built-in networking and orchestration. Perfect for research labs, AI startups, and enterprise R&D teams that need rapid scale-out compute.
- 1-click cluster deployment
- InfiniBand fabric and distributed storage
- Supports PyTorch DDP, Ray, and MPI workloads
- Customizable node templates and auto-teardown options

Managed Kubernetes for AI
GPU-Ready Kubernetes, Fully Managed
Run containerized AI/ML workloads without worrying about infrastructure management. NeoCloudz’s managed Kubernetes service includes autoscaling, monitoring, and MLOps integrations — tuned specifically for GPU-intensive applications.
- NVIDIA GPU operator pre-installed
- Auto node scaling and health monitoring
- CI/CD integrations for continuous model deployment
- Enterprise SLAs and private networking

AI Storage
High-Throughput Storage Optimized for AI Pipelines
Move massive datasets at GPU speed. Our AI Storage platform delivers parallel I/O performance and low-latency access for datasets, checkpoints, and embeddings.
- NVMe-backed distributed architecture
- POSIX-compliant, S3-compatible interface
- Tiered hot/cold storage with data lifecycle policies
- Integrated with AI Cloud and Clusters

JupyterLab® Applications
Instant Multi-Node Clusters — Built for Scale
Launch pre-configured JupyterLab® environments with GPU acceleration, data connectors, and package management. Perfect for researchers, educators, and rapid experimentation teams.
- Isolated containerized notebooks
- Built-in data mounting and secret management
- Integration with NeoCloudz AI Cloud APIs
- Support for TensorFlow, PyTorch, Hugging Face, and RAPIDS

Hardware Platforms
Powered by the World’s Most Advanced GPUs
NeoCloudz operates exclusively on the latest NVIDIA architectures — offering peak performance, energy efficiency, and scalability for AI workloads.
- NVIDIA Blackwell GPUs – For frontier-scale model training (B200 available now • B300 coming Q1 2026)
- NVIDIA H200 GPUs – For inference, fine-tuning, and production workloads
- InfiniBand Networking – 400 Gb/s interconnect for distributed training
- NVMe Storage Fabric – High-speed, low-latency parallel file system
Your AI Infrastructure Starts Here.
From single GPU instances to enterprise clusters — NeoCloudz gives you the performance and control you need to build the future of AI.